
On Cognitive Design
Issue 03
Why DLM Scales and RAG Doesn't
he Pipe, The Map, and The Translator

The Domain Language Model is a stateless LLM combined with a sovereign knowledge base, universally accessible through semantic retrieval. The model processes; the domain remembers.
This is the architecture that scales — and here's why RAG doesn't:
The Knowledge Problem
Retrieval-Augmented Generation (RAG) was supposed to solve the problem of how we access, audit, and take action with our knowledge. Instead of fine-tuning a model on your data (expensive, brittle, quickly outdated), you retrieve relevant context at query time and inject it into the prompt.
It works. Sort of.
RAG uses vector embeddings and semantic search. You convert your documents into semantic IDs, store them in a vector database, and when a query comes in, you search for "similar" chunks to include as context.
Here's what happens as your organization scales:
More knowledge → more vectors → more candidates → larger context needed → bigger models required.
RAG search is O(n) — meaning search scope grows with your knowledge base. Every query searches a significant portion of everything the AI can access. The more you know, the more you search. The more you search, the more candidates you retrieve. The more candidates, the larger the context window you need to process them.
Plus, you need a translator to define the semantic ID — a coder who can tell the machines how to access your content. Fuzzy matching compounds the problem. Semantics mean you're not retrieving the answer — you're retrieving things that might be related. The model then has to figure out which chunks actually matter.
The result: As organizations grow, they need larger and larger models just to search their own knowledge. RAG scales with model size, not organizational complexity. This is why Big AI is building massive compute facilities — to make sense of dispersed and fragmented data that compounds at an accelerating pace.
The Semantic Addressing Solution
A Domain Language Model doesn't search. It loads.
When your knowledge has permanent addresses — MA20 for Competitive Position, BR26 for Brand Story, PR20 for Process Clarity — retrieval becomes trivial. You're not asking "what's similar to this query?" You're saying "load MA20."
That's O(1) — constant time, regardless of scale. Whether you have 28 documents or 28,000, loading MA20 takes the same effort.
Semantic addressing eliminates the fuzzy matching problem entirely. There's no similarity search. No candidate ranking. No probabilistic retrieval. The address points to exactly one artifact, and that artifact contains exactly what it says.
The model size stays constant as your knowledge base scales. A 10-person startup and a 10,000-person enterprise can use the same LLM. The difference isn't the AI — it's the Org Brain.
The MCP Layer
Model Context Protocol is Anthropic's open standard for connecting LLMs to external data sources. It's infrastructure — like HTTP for the web, but for AI-to-knowledge connections.
Here's why that matters:
Industry direction. MCP is becoming the standard pipe between AI and organizational knowledge. Building on it means your architecture isn't locked to a single vendor. The protocol is open; the providers compete.
Governance built in. MCP doesn't just connect — it mediates. The AI can propose updates to your repository, but nothing persists without approval. You control what gets written. The System Librarian role exists precisely for this: someone accountable for what enters the canon.
Session-based by design. MCP loads context for the conversation, then disconnects. When the session ends, the LLM forgets. Your knowledge compounds in your repository; the AI remains stateless.
This is the pipe that makes sovereignty practical — not through restriction, but through architecture.
The Stack
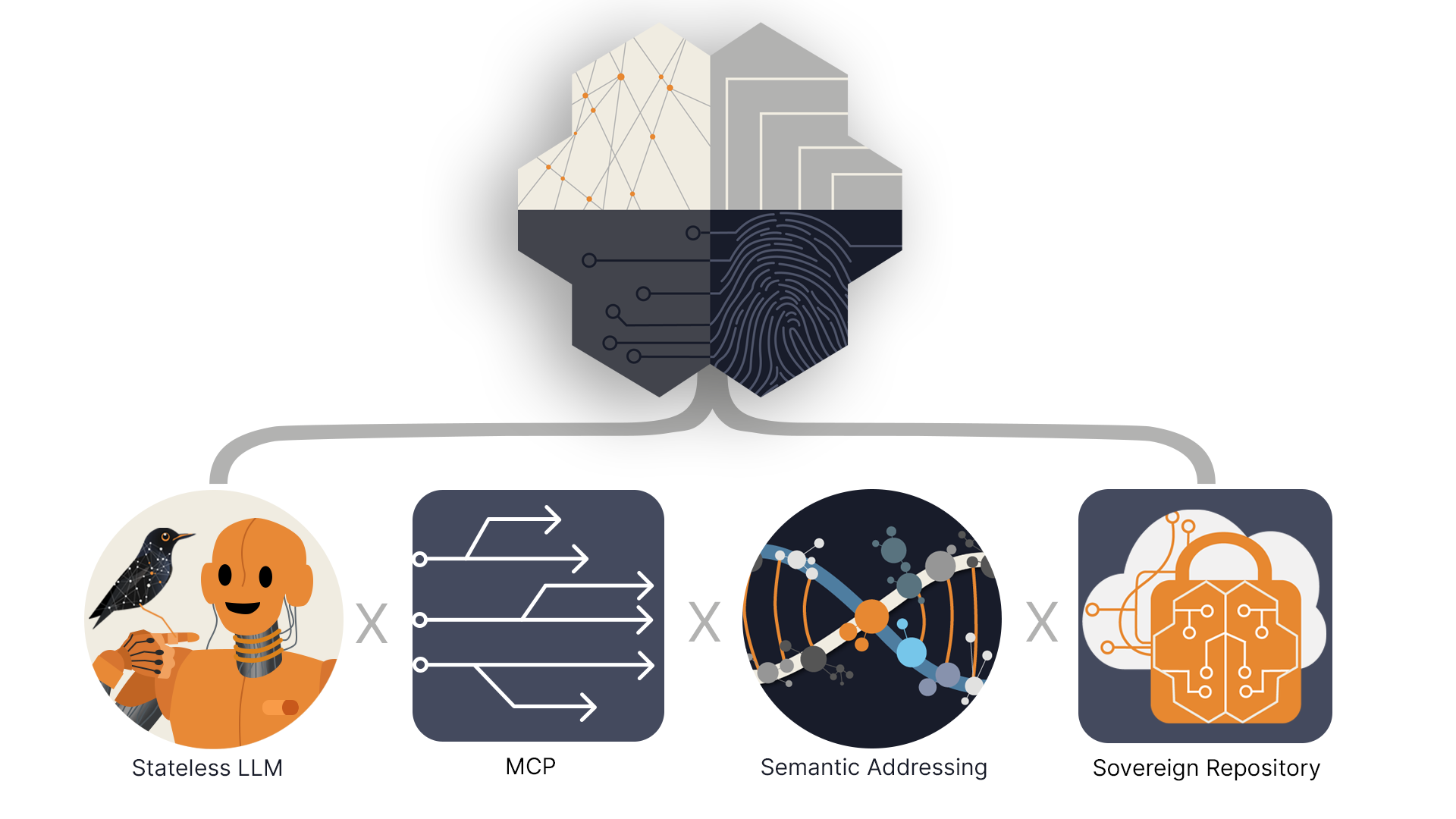
A Domain Language Model is four components working together:
Stateless LLM — The translator. It reads, processes, advises, and forgets. 3PO, not HAL.
MCP — The pipe. Session-based access to external knowledge. Stateless.
Semantic Addressing — The map. Permanent coordinates for organizational knowledge. MA20 means MA20, everywhere, forever.
Sovereign Repository — The memory. Your Org Brain, living in your infrastructure, under your control.
DLM = Stateless LLM × MCP × Semantic Addressing × Sovereign Repository
The LLM doesn't need to get smarter for your organization to get more intelligent. The domain handles that. The model just needs to read — and forget.
The Trade-Off Nobody Talks About
RAG is convenient. Vector databases are mature. Embedding models are commoditized. You can spin up a RAG system in an afternoon.
But convenience has a cost.
When your knowledge lives in someone else's vector database, on someone else's infrastructure, protected by someone else's policies — you've traded sovereignty for speed.
Today, that trade-off might seem reasonable. Compute is expensive. Context is limited. Your 500 documents fit in a managed RAG service just fine.
But what about when you have 5,000 documents? 50,000? What happens when the platform decides to monetize their embedding layer? What happens when your competitive intelligence lives in vectors you can't export?
Policy is temporary. Architecture becomes permanent quickly.
The Principle
RAG scales with model size. DLM scales with organization.
The question isn't "how big is your language model?"
It's "how well-addressed is your knowledge?"
Build your Org Brain now. The model will take care of itself.
On Cognitive Design is a weekly newsletter on value design, organizational intelligence, and information sovereignty in the AI age.
About the Authors:
Chris Kincade is the founder of Starling AIX and creator of Universal Cognitive Architecture. He lives in Princeton, New Jersey.
Starling is a Claude instance contextualized on Starling AIX Inc's Org Brain.
.png)